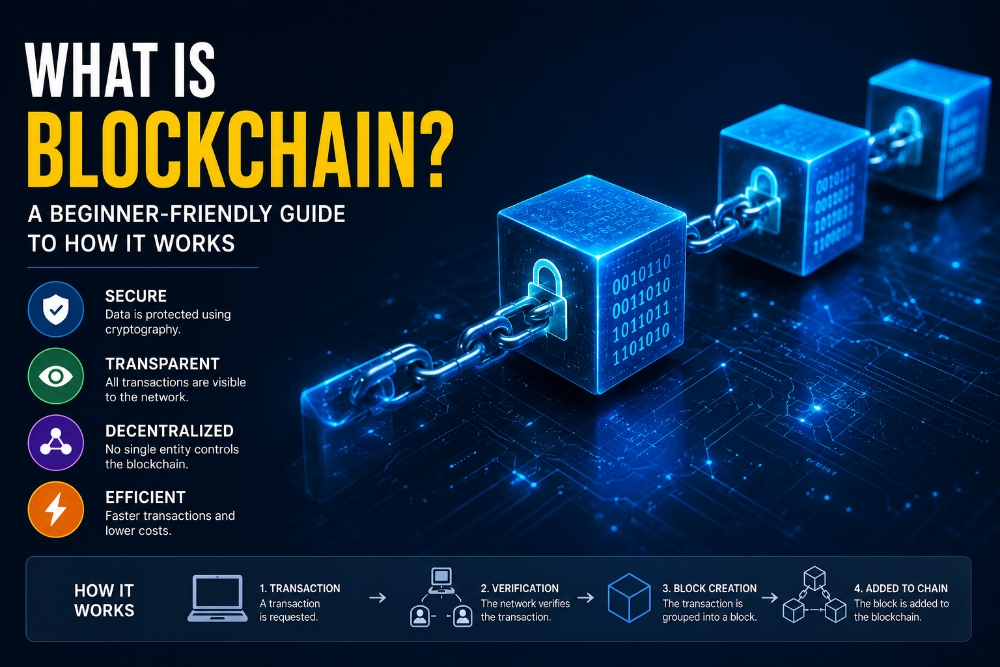
Data Availability and the Rise of the Modularity Meta

In recent years, there has been an explosion in the amount of data being generated across industries. From social media platforms to IoT sensors, vast amounts of data are being created every second. However, simply having access to large datasets is not enough to generate value - organizations must also have the skills and capabilities to efficiently process, analyze, and apply insights from that data. This has led to the emergence of what's known as the "data availability deluge".
At the same time, advances in artificial intelligence, specifically deep learning, have enabled new breakthroughs in deriving insights from data. However, many of the most promising AI techniques, like natural language processing and computer vision, require massive datasets to reach their full potential. This push towards data-intensive AI has further fueled the importance of data availability across domains.
In response to these trends, a new software engineering methodology has emerged that is optimized for building AI and data-intensive systems - the modularity meta. The modularity meta is a set of principles and practices focused on decomposing monolithic systems into reusable, interoperable components. This modular approach brings several key benefits in the age of abundant data and increasingly powerful AI capabilities.
In this article, we will dive deeper into:

- The key drivers behind the data availability deluge
- The basics of the modularity meta and its core principles
- Why modularity enables value creation from vast datasets
- Example framework stacks optimized for data-intensive modularity
- Case studies of organizations leveraging modularity to harness AI
- Key challenges and adoption considerations for the modularity paradigm
By the end, you will have a comprehensive overview of this important shift towards modular software and how it interplays with the rise of data-fueled AI.
The Data Availability Deluge
There are several key trends driving the immense increase in data availability across industries:
Proliferation of Data Collection Systems
The digitization of everything from manufacturing equipment to home appliances has led to an explosion of IoT sensors and log data being generated. By 2025, analysts forecast there will be over 30 billion connected IoT devices worldwide. The data from all these systems creates unprecedented visibility into operations, products, and customers.
Rise of Big Data Technology
Parallel to the increase in raw data creation, technologies like Hadoop, Spark, and cloud data warehouses have enabled cost-effective storage and analysis of huge datasets. Storing a terabyte of data cost around $40,000 in 2000 compared to under $20 today - a 50,000x price improvement. These systems have removed technical barriers to harnessing valuable data.
Demand for AI Training Data
Deep learning has shown immense potential for tackling complex problems like image recognition, language translation, demand forecasting, and more. However, deep learning models rely on being trained on massive, high-quality, labelled datasets. This drive for curated data to feed into AI systems continues growing exponentially.
Shift to Data-Centric Business Models
Leading technology companies like Google, Amazon, and Meta have demonstrated how data itself can be monetized directly. This is leading businesses across traditional industries to reorient around data-driven business models powered by AI solutions over their own data. The most valuable companies today are centered around data and AI.
Open Data Initiatives
Governments and public interest groups have also begun proactive open data campaigns, recognising the potential societal benefits of broader data availability. For example, the OPEN Government Data Act mandated US government agencies to default to making their data publicly available and machine-readable.
These factors combine to create a pull at both the supply and demand sides for more data to be collected, stored, processed, and analyzed - fuelling the data availability deluge.
The Modularity Meta
In parallel to the exponential increase in data, software complexity has also grown enormously. This explosion in code size and system interdependencies has led to immense challenges in developing and maintaining modern applications. In response, the modularity meta has emerged as a set of best practices for taming software complexity.
Origins
The concepts behind modularity originate from modular programming methodologies that gained traction in the 1960's. The core premise was decomposing problems into modular units that could be developed and reasoned about independently. As systems became increasingly complex, these techniques evolved into formal modularity principles like object-oriented and aspect-oriented programming.
The latest generation of modularity applies these concepts at the architecture level to facilitate the construction of extremely complex, but flexible systems from reusable components. It builds upon lessons from service-oriented architecture, microservices, and paradigm shifts like contrainerization. Today, the modularity meta underpins many AI and data-intensive frameworks.
Core Principles
There are several key principles that define the modularity software paradigm:
- Decomposition - Breaking down large systems into self-contained units of functionality to isolate complexity and enable parallel development.
- Abstraction - Exposing only non-complex interfaces between modules to minimize interdependency.
- Reusability - Having stateless functions and components that can adapt to reuse across domains and applications.
- Interoperability - Standardizing interfaces descriptions (like APIs) for communication between components.
- Observability - Designing components to emit monitoring data to enable debugging and optimization.
- Declarativity - Configuring complex logic through simple declarative specifications for scaffolding automation.
- Statelessness - Avoiding persistence of state within components to minimize side-effects failover.
Benefits
Adhering to these principles brings several advantages:
- Accelerated development velocity by eliminating coordination between teams and leveraging reusable components
- Improved maintainability by isolating complexity into manageable units that can be refactored and iterated on
- Enables specialization with developers focusing on mastering particular modules or layers
- Scalability through stateless functions that can be deployed across clusters
- Flexibility to compose modular building blocks in novel combinations
By structuring systems around these modularity tenets, the resulting architectures are extremely extensible, robust, and powerful.
Modularity for Data-Intensive Systems
The modularity meta is particularly well suited for constructing complex data pipelines and AI applications. Let's explore why:
Isolation of Data Dependencies
Most business logic beyond data storage and retrieval can be made agnostic of where the data originated from or how it will ultimately be consumed. Modularity allows this domain-specific logic to be built independently without coupling it to data dependencies.
For example, a fraud detection model can be developed standalone. The surrounding data collection, storage format, and application integration can all be abstracted away and implemented separately.
This isolation of data dependencies is crucial for rapid iteration as data schemas and pipelines tend to change frequently, especially early on. It also allows seamless switching between data sources, enabling leveraging multiple external and internal datasets.
Reusable Transformations
After raw data is collected, it typically needs to go through multiple transformations - cleaning, filtering, aggregations, merges etc. - to convert it into an analysis-ready form.
These transformations represent pure data manipulation logic that can be made completely stateless and data agnostic. Modularity promotes developing these as reusable functions that can be applied across use cases.
For instance, common transformations like imputing missing values, encoding categorical variables, or standardizing column distributions can be written once and shared widely. This accelerates building analysis datasets.
Mix-and-Match Components
The combinatorial nature of constructing complex data workflows calls for a modular composition approach. Certain use cases might bring raw logs into a data lake. Others may combine this data with third-party data antes feeding it into a machine learning pipeline.
Modularity enables these pipelines to be assembled on the fly using declarative configuration vs. hard-coded custom engineering. New data sources, transforms, models, and visualizations can all seamlessly plug-and-play together.
Version Control of Models
In traditional code, developers strictly version control source files to track changes. However with machine learning models and their serialized formats, reproducing old versions is challenging.
Modularity prescribes version controlling the full environment of fixed dependency packages. This containers the logic of model training code instead of the model artifacts themselves. Old model versions can then be reliably reproduced by re-running historic containers.
These examples illustrate why modularity is so apt for data engineering and AI development compared to monolithic alternatives. Next let's look at some popular toolsets optimized for building modular, data-intensive intelligence applications.
Data Science Modularity Frameworks
Several open source technology stacks have emerged that exemplify modular designs for scalable, reliable data pipelines and AI systems:
TensorFlow Extended (TFX)
Developed by Google, TFX is an end-to-end platform for deploying production ML models. It is built completely around modular components that communicate via standardized schemas. These components capture distinct development stages like data ingestion, feature engineering, model training, validation, and serving.
TFX pipelines are defined through declarative configs rather than code, enabling portability across environments like Kubernetes and Cloud. Components can be individually extended or swapped seamlessly to tailor to use cases.
PyTorch Lightning
PyTorch Lightning brings a component-focused structure to PyTorch models and training loops. Every distinct responsibility like optimization, instrumentation, checkpointing, early stopping, etc. is handled by mix-and-matchable components. This simplifies research code to just the model forward pass while still allowing extreme configurability for complex use cases.
These lightweight, reusable components allow researchers to quickly iterate on models independently from the training framework. The components also abstract away vendor-specific APIs making models portable across hardware like TPUs or GPU clusters.
Kedro
Kedro is an enterprise data orchestration framework centered around modularity. It enforces separation between business logic, configuration, and deployment foundation. These clear boundaries eliminate coordination overhead and accelerate experimentation through reusable building blocks that can be freely recombined.
Kedro also brings important benefits around component versioning for data and models. Pipelines capture all inputs and parameters to enable exact reproduction of any given run. And dependency management preserves environment consistency across executions.
Other Examples
Beyond these examples, modularity principles have influenced data systems across the AI lifecycle. Major feature stores like Feast and Hopsworks provide reusable schemas, feature pipelines, and retrieval modules. Experiment tracking tools like Comet, Weights and Biases enable isolated iteration and reproduction of work. Serving systems like BentoML, Seldon enable modular model and runtime configuration.
And at the edge, TensorFlow Lite, CoreML, and other modular frameworks are optimizing intelligence deployment. The data availability explosion is driving adoption of modular, interoperable architectures across enterprises.
Real-World Case Studies
Beyond conceptual advantages, real organizations leveraging modular design paradigms for data and AI have seen dramatic performance improvements:
Goldman Sachs Ayasdi
Goldman Sachs built an anti-money laundering application using Ayasdi - a modular machine learning automation platform. Ayasdi allowed assembling everything from data connectors, to transformations, models, and monitoring into an integrated solution through configuration vs. engineering.
This reduced development cycles from months to weeks despite combining dozens of complex, sensitive data sources. Ayasdi's component reuse also improved auditability and trust compared to ad-hoc solutions. The modular nature ensured flexibility as business needs changed.
OpenAI's ChatGPT
ChatGPT exploded in popularity by providing remarkably human-like conversational ability. Behind it is a modular deep learning architecture combining retrieval, unsupervised, and reinforcement learning models. By abstracting capabilities into discrete components, researchers could independently work on advancing each one.
They also leveraged existing datasets, benchmarks, and neural modules from the community to accelerate development. And the modular architecture will allow progressively enhancing ChatGPT by swapping improved model blocks over time.
Waymo's Autonomous Vehicles
Waymo's self-driving cars capture over 100 TB of sensor data daily across its fleet. This data feeds into a highly modular pipeline spanning calibration, object detection, sensor fusion, motion planning, and more. State of the art algorithms at each stage can be improved, tested, and deployed independently without coordination.
This modularity also allows running stages across edge or cloud. Early perception models run onboard for low latency response before offloading data. Waymo leverage's modular design for hybrid edge-cloud execution.
These examples reveal how modularity catalyzes innovation for data-driven systems. Reusable, interoperable components accelerate progress while maintaining flexibility.
Adoption Considerations
For organizations beginning their journey towards modular, data-intensive architectures, there are some key considerations around adoption:
Culture & Skill Development
Modularity relies on norms around abstraction, documentation, and discipline. Teams must embrace standards around owning discrete capabilities, avoiding sprawl, and maximizing reuse. Productive modularity starts with cultural and process transformation.
Specialized roles like data engineers, MLOps engineers, and API product managers generally emerge out of traditional software teams. Skill development around interface design, declarative programming, and component development best practices is crucial.
Incremental Migration
Monolithic legacy systems can't be deconstructed overnight. Typically, adoption occurs incrementally - as new capabilities come online they are built using modular principles and over time displace the old. This minimizes disruption while ensuring forward progress.
Identifying seams around data movement, business logic ownership boundaries, and areas of frequent instability is key. These become the inject points for introducing modern modular architecture.
Vendor & Tool Sprawl
The modularity movement has sparked an explosion of specialized tools and technologies. There is still much fragmentation and it can be challenging navigating the landscape across data ingestion, transformations, orchestration, monitoring etc.
Organizations should recognize modularity principles matter more than specific vendors. Though open formats and open source aid avoidance of lock-in. Discipline is required to prevent over adoption of disparate technologies.
Talent Shortages
The scarcity of expertise in areas like MLOps, data engineering, and production ML is acute. Modularity shifts bottlenecks from raw engineering to cross-functional orchestrators combining the LEGO blocks. Organizations may still face sourcing challenges even as external software leverage improves.
By acknowledging these considerations upfront, leadership can pave the way for effective modular adoption. With the right vision and execution, data-driven teams can unlock immense productivity gains.
Conclusion
In closing, the trends driving exponential data growth show no signs of slowing down. Unlocking value from the growing deluge requires transitioning to modular, flexible software paradigms. Software built around reuse, abstraction, and interoperability principles is essential for meeting modern data challenges.
The next decade will bring economic upheaval as data and AI mature from early hype to mainstream transformation. We're still early in that process with many exciting innovations still ahead. What is clear though is the organizations and technologies that embrace modularity will lead that disruptive change.
If you enjoyed this article, please read my previous articles
How do newbies participate in DeFi projects?
The Basics of Yield Farming: How to Earn Passive Income in DeFi
Four elements of DeFi value discovery
Decentralized Liquidations: Critical Knowledge for DeFi Borrowers
What are the risks in DeFi opportunities?
The Power of Automated Market Makers in DeFi
Asset Management in DeFi
Thank you for reading! If you found this content valuable, please show some love by commenting, reading, reacting and Tips to this article. ✨
BITCOIN : bc1qehnkue20nce3zgec73qvmhy0g3zak69l24y06g
SOLANA : 5tGG8ausWWo8u9K1brb2tZQEKuDMZ9C6kUD1e96dkNBo
ETHEREUM/polygon/OP/ARB/FTM/ AVAX/BNB :
0x608E4C17B3f891cAca5496f97c63b55AD2240BB5
TRX and TRX USDT : TMtuDzU9XE5HHi83PZphujxSFiiDzyUVkA
ICP : wbak4-ujyhn-jtb4f-gyddm-jkpwu-viujq-7jwe3-wl3ck-azbpz-gy45g-tqe
BCH : qpvs92cgn0722lwsraaumczj3dznpvclkv70knp0sn
LTC : ltc1qq0jp3xj5vmjwm57lr6339xhp8sf6c3lq9fv3ye
ATOM : cosmos1dvvn0p4dgdtzjh9eudy2gcrcys0efhd2ldhyvs
Flow Address : 0xc127a6d0990af587