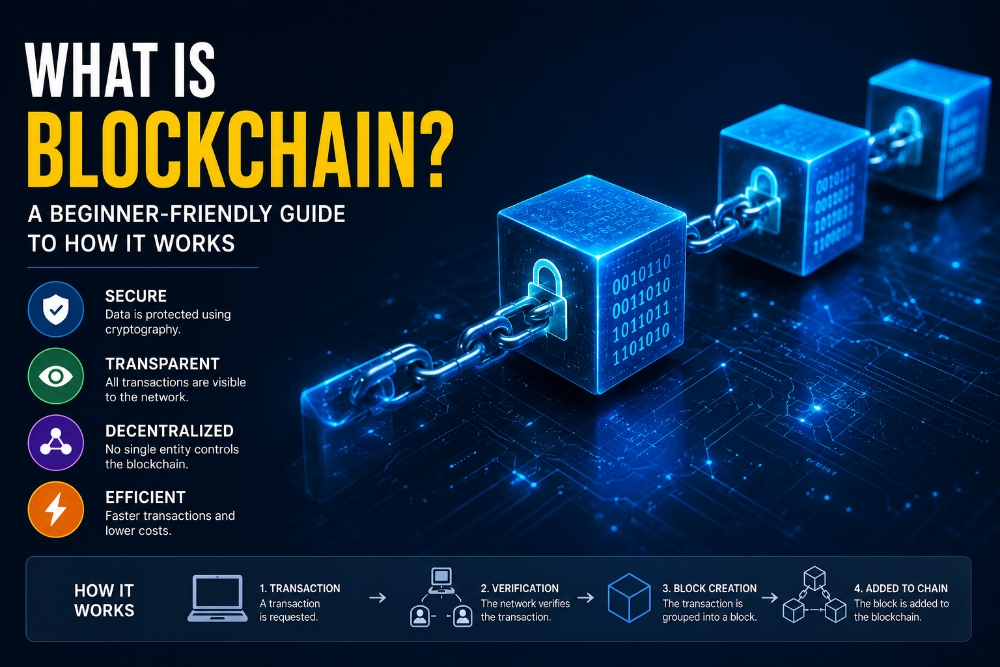
How to setup RAG with VectorDB

Mainly it’s heavily in use for LLM-based apps, chatbots AI customer support, internal knowledge assistants etc.
📊 Brief overview
Let’s create a ticker-specific RAG database table example using Pinecone. In my project I needed to map stock, crypto name: ticker symbols to extract just the ticker symbol. I have as well a Youtube video what you can check bellow. 👇️
https://youtu.be/QDe3Gi2tXR8
Database setup
As mentioned I used Pinecone but there are as well other options like using Redis and even Postgres has some support.
So ones you have created an account create a new index(table)
There are many options and it depends of course on the LLM model you use. If you use GPT then by all means use one of the predefined GPT embeddings. There is as well Llama and Microsoft configuration, for my use case I made a “Manual configuration” due to embeddings based on all-MiniLM-L6-v2 model in HuggingFace.
https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2

NOTE: It’s really important to setup configs correctly as otherwise embeddings won’t work. My Metric: cosine, Dimensions: 384, Type: Dense your’s however may differ.
Ones created and running extract your API key and add to your .env for further embeddings.
📊 Prepare Dataset
Bellow you can see fraction of my .csv just to get a glimpse what I am embedding
text,label TSLA,Tesla AAPL,Apple MSFT,Microsoft BABA,Alibaba Group Holding Limited ...
For LLM I recommend using Jupyter or Google Colab rather then a regular IDE.
import os
from dotenv import load_dotenv
from sentence_transformers import SentenceTransformer
from datasets import load_dataset
from pinecone import Pinecone
load_dotenv()
pc_api_key= os.getenv("PINECONE_API_KEY")
dataset = load_dataset("Mozes721/stock-crypto-weather-dataset", data_files="crypto_mapppings.csv")
df = dataset["train"].to_pandas()
In above code I just import required packages like pinecone, and sentence_transformers used for embeddings.
I stored my training data in https://huggingface.co/new-dataset due to the fact it’s LLM related same as for fine tunning rather then locally, but that is individual choice.
Build Alias Map
# Step 2: Create alias map
alias_to_ticker = {}
for _, row in df.iterrows():
ticker = row['text'].upper()
name = row['label'].lower()
alias_to_ticker[ticker] = ticker
alias_to_ticker[name] = ticker
# Optional: add lowercase ticker too
alias_to_ticker[ticker.lower()] = ticker
# Step 3: Prepare for embedding
aliases = list(alias_to_ticker.keys())
tickers = [alias_to_ticker[a] for a in aliases]
# Embed
model = SentenceTransformer('all-MiniLM-L6-v2')
embeddings = model.encode(aliases, convert_to_numpy=True)
# Step 5: Load Pinecone table
pc = Pinecone(api_key=pc_api_key)
index = pc.Index("stock-index")
So alias map is created and in the for loop iterate over rows on text and label. Append to alias tuple both name and ticker( in my mappings it should work on both ends if AAPL given should return AAPL if Apple then AAPL).
Then we fetch the model we want to embed it to and encode by converting to numpy ad then for now just load the index table.
Embed & Store in Pinecone
# Prepare vectors in correct format
vectors = []
for i in range(len(aliases)):
vectors.append({
"id": f"stock_{i}",
"values": embeddings[i].tolist(),
"metadata": {"ticker": tickers[i], "alias": aliases[i]}
})
# Batch upsert to avoid 2MB limit
batch_size = 50
total_batches = (len(vectors) + batch_size - 1) // batch_size
for i in range(0, len(vectors), batch_size):
batch = vectors[i:i + batch_size]
index.upsert(vectors=batch)
batch_num = i // batch_size + 1
print(f"Batch {batch_num}/{total_batches} has been embedded and uploaded ({len(batch)} vectors)")
print("All city batches completed!")
The vectors should be prepared in an array, we go through a for loop in aliases. Then append to vector and have id, values and metadata defined.
Uploading to Pinecone needs to be done in batches to avoid 2MB upsert limit. When its done with batch_size we can upsert to stock-index table.

🤖 Querying with RAG
The testing face should be quite simple as long as data has been embedded properly and same LLM model is used.
import os
from dotenv import load_dotenv
from sentence_transformers import SentenceTransformer
from pinecone import (
Pinecone
)
class EmbeddingStockMapper:
def __init__(self, model_name: str, pinecone_api_key: str):
# Initialize the embedding model
self.model = SentenceTransformer(model_name)
pc = Pinecone(api_key=pinecone_api_key)
self.index = pc.Index("stock-index")
def get_stock_ticker(self, query):
# Get embedding for the query
query_embedding = self.model.encode(query, convert_to_numpy=True)
# Search in Pinecone
results = self.index.query(
vector=query_embedding.tolist(),
top_k=1,
include_metadata=True
)
if results.matches:
return results.matches[0].metadata['ticker']
return None
# Initialize the mapper
load_dotenv()
pc_api_key= os.getenv("PINECONE_API_KEY")
mapper = EmbeddingStockMapper(model_name="all-MiniLM-L6-v2", pinecone_api_key=pc_api_key)
So we initialize the model with all-MiniLM-L6-v2 same as used before in embeddings. Then create a method get_stock_ticker that will encode the query passed to it. It will then return a result.matches[0].metadata[‘ticker’] as per own specification that most closely matches.
test_queries = ["AAPL", "Apple Inc.", "apple", "What is the current stock price of Tesla.", "Google", "google", "TSLA", "Tesla", "tesla", "Microsoft Corporation", "microsoft"]
for query in test_queries:
ticker = mapper.get_stock_ticker(query)
print(f"Query: {query} -> Ticker: {ticker}")
//Output
Query: AAPL -> Ticker: AAPL
Query: Apple Inc. -> Ticker: AAPL
Query: apple -> Ticker: AAPL
Query: What is the current stock price of Tesla. -> Ticker: TSLA
Query: Google -> Ticker: GOOGL
Query: google -> Ticker: GOOGL
Query: TSLA -> Ticker: TSLA
Query: Tesla -> Ticker: TSLA
Query: tesla -> Ticker: TSLA
Query: Microsoft Corporation -> Ticker: MSFT
Query: microsoft -> Ticker: MSFT
Above you can see how it gracefully returned ticker symbols as per my request!
In all honesty I was astonished by the results. RAG is slowly getting traction and I think a this is a lot better approach even if there is a learning curve compared to just using ChatGPT API calls. But most of us have simple need for AI implementation so using the whole AI model can be deemed as an “overkill”.
My repo you can find here for any questions feel free to ask.