Snow Falling From The Clouds
The Snowflake story comes from an unusual beginning however is poised to be one of tech’s most dominant companies. The company has a net revenue retention rate of 173% which is almost unheard of. NRR is the number of customers that continue to increase spending once they have joined.
The company also boasts a superstar lineup of talent. Founded by three database PHDs and steered by the hard-charging dutchman Frank Slootman who is probably the best enterprise technology CEO in the world.
So, how did Snowflake come about?
Before the cloud, companies had to purchase physical servers to store data. This data was originally stored on tapes and required large amounts of space. There was also the continual cost to maintain and upgrade the hardware.
These systems were very fragile, highly complex, and required a team of internal IT to manage.
This was nothing short of a splinter for company executives to deal with.
Small businesses couldn’t even collect data this way because of cost so, they stuck to good old pen and paper.
That was until our mate Jeffrey Bezos started his everything store.
During this period, Amazon was growing like crazy and was building enormous data centers across the world to host its data. They would only use a fraction of this capacity and realised that they could rent this space to other companies. This gave birth to cloud computing.
The cloud made it significantly cheaper to host your data with Amazon. Mainly because you didn’t have to worry about constantly upgrading your systems, purchasing computer power, and hiring staff to manage it. It was better, faster and cheaper.
This made it economical for all businesses small and large to collect data. But there was just one problem, cloud computing only solved the storage component of databases.
Databases are made up of two major components. Computation and storage. Cloud takes care of storage and a data warehouse is used for computation.
A data warehouse is a system used for reporting and data analysis. The data warehouse is what is used to run searches (queries) of the data. It maintains a copy of information from the source and is a transactional system.
A typical data warehouse architecture looks like the following;
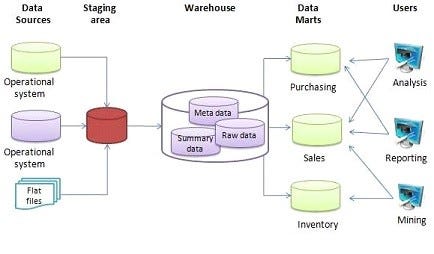
(Source: Wikipedia, Data Warehouse)
Most data warehouses use open-source code called MySQL. MySQL is a relational database system, which means that the data is stored in tables under different groups which are linked together.
See image below:
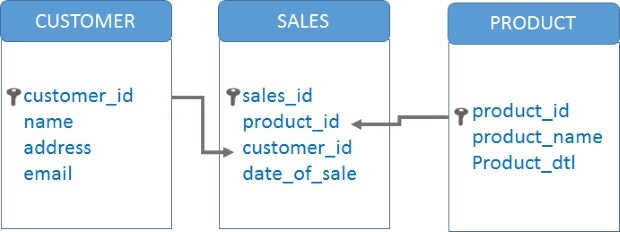
(Source: Google Images)
MySQL is a solid database, however, once the database is built it is extremely hard to change. Adding new tables and linking them to existing tables significantly impact the performance of the database. It makes it slower and harder to find queries. This requires more computing power as the complexity of the database increases.
Although the database had moved from physical servers to the cloud, companies still purchased physical data warehouses. These were expensive to run and the bigger the dataset the more computing power was needed.
Introduction to Snowflake
The name Snowflake comes from cloud computing, where Snowflakes fall from the clouds. Not a bad name if you ask me.
The original concept of Snowflake was developed by Mike Speiser, the Managing Director of Sutter Hill Ventures in San Francisco.
Sutter Hill has a different approach to venture than most VC firms. They prefer to analyse the tech landscape and incubate companies within their own walls.
Speiser wanted to create a system to increase the speed of database storage. He was introduced to Benoit Dageville who was a top software architect at Oracle.
Benoit didn’t like the original concept, he suggested that the speed of the database storage was not the issue. This issue was in computation. The computational part involved pulling together scrappy pieces of information, processing them and quickly turning them into insights.'
Benoit wanted to focus on the computational side rather than the storage side.
They would create a data warehouse in the cloud, a more effective and less expensive way to handle large amounts of data. In the cloud, there would be 0 limitations on storage and computing resources.
Benoit needed a partner and he happened to know the perfect person. Thierry Cruanes worked with Beniot at Oracle.
The pair were brainstorming possible business ideas whilst still at Oracle.
It was until Speiser’s call that the pair took these thoughts seriously.
Sutter Hill invested $1million to get things started. Benoit and Thierry insisted that they did not want to be in charge and wanted to focus on product innovation.
Speiser would be the temporary CEO in the meantime.
They bought a whiteboard and started to get things moving. They made 2 distinct choices in the first 6 months:
- To separate the storage of computing. The company would maintain only one copy of the data that is collected. It would be placed in the cloud for storage. Typical data warehouses hold a copy of the data within them. Snowflake would maintain only one copy.
- The data warehouse would map the data and draw records it needed. Any number of clusters of computers would be directed to the warehouse to access the same data at the same time.
This came with 2 main advantages:
- It meant there is only one version of truth within a company. Not a mish-mash of data from multiple different databases.
- It also meant that they could store customers’ data in an array of storage devices in the public cloud. E.g. one customer could be using Amazon and Google and still have the same performance.
The pair figured out how to re-design the data warehouse, now they had to figure out how they could increase the speed of data retrieval.
A problem with traditional data warehouses is that there are many computers trying to extract data at the same time. As company size increased there would be more and more computers trying to retrieve data at the same time.
Increasing computer demand, combined with changes to database structures (adding more tables), resulted in retrieval times that could be minutes or even days.
Traditional databases fetch a query by sourcing a single record at a time.
Fortunately, there was a young gentleman completing his Ph.D. on vectorized querying execution.
Marcin Zukowski was a Dutch computer scientist who had started a company in this area after college.
Benoit and Theirry knew that to get him on board would be a tough sell as he had already founded his own start-up. But they needed his expertise, so they decided to make him a co-founder. He accepted and joined the team.
Vectorized querying execution allows you to access a large number of records in each processing cycle rather than just one.
This tech made Snowflake’s data warehouse super fast. But not fast enough for the founders.
The founders also used something called micro partitioning. In databases, indexing and sorting are commonly used for a query to retrieve data.
Indexes create look-up structures that accelerate record retrieval. Partitioning breaks up a table into manageable chunks to focus the data retrieval.
Traditional databases require users to manually and explicitly enter the specific indexing and partitioning strategies.
The micro partitioning technique automatically breaks up the data into smaller chunks which can be more efficiently targeted.
This allows the Snowflake data warehouse to efficiently handle petabytes of data while, at the same time, making it easier to use. So users could be less specific and receive better, faster results.
The last part was solving the metadata layer (see data warehouse image). A key part of databases is the metadata layer, a system for mapping where your core data is stored.
Originally Snowflake engineers used MySQL for the metadata layer.
They found that MySQL was not capable of handling the mass amounts of computation that they required.
This was a company killer question. The team nervously searched for another language that they could use. Thankfully found Foundation DB.
With a superior architecture, an ability to handle more data, 10x greater performance, and the ease of use of an iPhone the team was ready to go to market. This period lasted for over two years before they released its first product to market.
SnowFlake Today
Snowflake is the world’s most prominent data cloud company. Snowflake has built several innovative products but for me, the most interesting is the data marketplace.
The data marketplace allows organisations to be able to purchase additional data that they may require.
Let’s say you’re expanding into a new market. But you would like to have more information as you evaluate the opportunity. Well with Snowf lake, you can purchase that information from someone who has more data in that area.
Snowflake figured out a way to exchange data from one company to another. Legally without compromising the seller’s competitive advantage. This is a huge benefit for companies that adopt Snowflake as they are not limited to the data within their company.
Additionally, Snowflake has a data exchange where businesses can share data within themselves or with other companies.
An example of data sharing in action was when data scientists from John Hopkins University created a model to predict the spread of the COVID-19 virus. They combined data from a range of different sources including transportation, air travel, virus modeling, and infection rates.
Using Snowflake’s data exchange, they made it available to the public on Snowflake’s public data exchange.
Within days, thousands of companies and healthcare systems were using this data to develop contingency plans to protect against the virus.
This highlights the impact of combining different types of data and making it available to others. This would not be possible without Snowflake’s technology.
What can we learn from the Snowflake Story?
The story of Snowflake follows a similar pattern that exists in breakthrough companies.
- Start with the Tech: Started by two highly technical founders, Beniot, Thierry and Marcin had deep expertise in database technology. As a team, they were able to fundamentally change the way that database computation was conducted. Leading to a product that was significantly better than all other alternatives.
- They also understood the customer needs in a visceral way, from their time at Oracle
- Prove the tech before selling. For enterprise startups, the product risk is a lot higher. You can’t sell a product to General Motors that is half-finished and buggy. The software needs to deliver value, be reliable, and have strong support. The 2-year stealth period allowed the team to perfect the product and prove the technology before going to market. So that when they approached big companies they could deliver on their promises with little risk.
- Just Stay Alive. Have the resources to survive. With a world-class founding team and backed by Sutter Hill, the company was able to raise enough money to stay alive, have higher talent, and transition from start-up to grown-up.
- What got you here won’t get you there. After the company had figured out what it’s selling and to whom, it’s time to ramp things up. Typically start-ups run into hurdles because now it’s about maximising the potential of the company through rapid growth and scale.
- This is where companies need to hire specific people with these core skills. Snowflake was able to get the best in the game, Frank Slootmen.
- He brought a team of people that he worked with before that were able to make the changes necessary to maximise the growth of the company.
There is a lot to learn about this story in regards to how innovation has impacted certain areas. The cloud solved one problem but created another problem in computation.
The combination of the right people, the right resources, and the right execution allowed Snowflake to captialise in this area that was not obvious to the market at the time.
As Snowflake continues to grow it could become one of the world’s most powerful companies. As they will be responsible for making your data useful and easily accessible no matter how big or small you are.
Anyway, that is all for this month, hope you enjoyed it.
Please share this with just one person if you found it interesting!