Mind Mapping Machine Learning for Intuitive Understanding (Part 1)

Take a quick tour around the building blocks of Machine Learning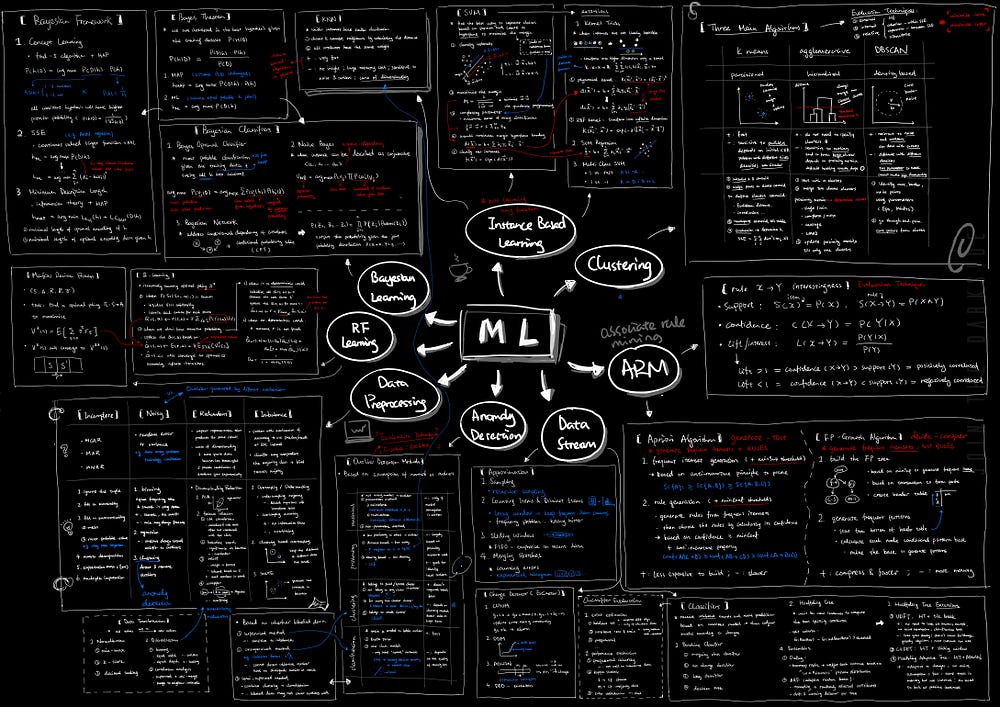 Handwritten Cheatsheet of Machine Learning Topics
Handwritten Cheatsheet of Machine Learning Topics
download the high-resolution cheatsheet from the website:
Data Analytics | Visual Design Studio
Free data Analysis tutorials and downloadable notes for data science lovers.
1. Association Rule Mining (ARM)
Given a set of transactions, find rules that will predict the occurrence of an item based on the occurrences of other items in the transaction.

Core Concepts:
- support: the fraction of transactions that contain an itemset X
- confidence: how often items in Y appear in transactions that contain X
- lift: lift is calculated as confidence divided by support, taken into account of statistical independency of rules
Algorithms:
Apriori Algorithm
- a generate and test approach
- generate candidate itemsets and test if they are frequent
- apriori principle: if an itemset is frequent, its subsets must also be frequent
- anti-monotone property: support of an itemset never exceeds the support of it subsets
- rule generation is based on frequent itemsets and the minimum threshold of confidence
FP Growth Algorithm
- a divide and conquer mining approach
- build FP tree which a compact representation of the transaction database and it is well ordered by frequency
- easy to traverse and mine conditional patterns based on each node
2. Clustering
Cluster Analysis: finding groups of objects such that objects in a group will be similar to one another and different from the objects in other groups.
Algorithms:
 K means Clustering
K means Clustering
- partitional clustering approach
- randomly selected initial centroid and assign points to the closest centroid
- recompute the centroid until they no longer change
Agglomerative Clustering
- hierarchical clustering approach
- merge individual cluster together based on the proximity matrix
- proximity matrix is calculated by a specific policy, e.g. MIN, MAX, general average, Ward’s Method etc
DBSCAN
- density-based clustering approach
- all points are categorized into three types: core point, border point and noise point
- determined by two parameters: a specified radius (Eps) and the minimum number of points within range (MinPts)
- clusters are formed around core points
How DBSCAN works and why should we use it?
First of all, this is my first story on medium, then sorry if I’m doing something wrong. Secondly, I’m not fluent in…
3. Instance-Based Learning
Not all of the learning algorithms are generalized by learning a function. Instance based learning is a class of algorithms that do not learn algorithm but rather directly compare to known examples.
Algorithms:
k-Nearest Neighbour (kNN)
- classification based on the labels of the nearest k neighbours
- all attributes have the same weight
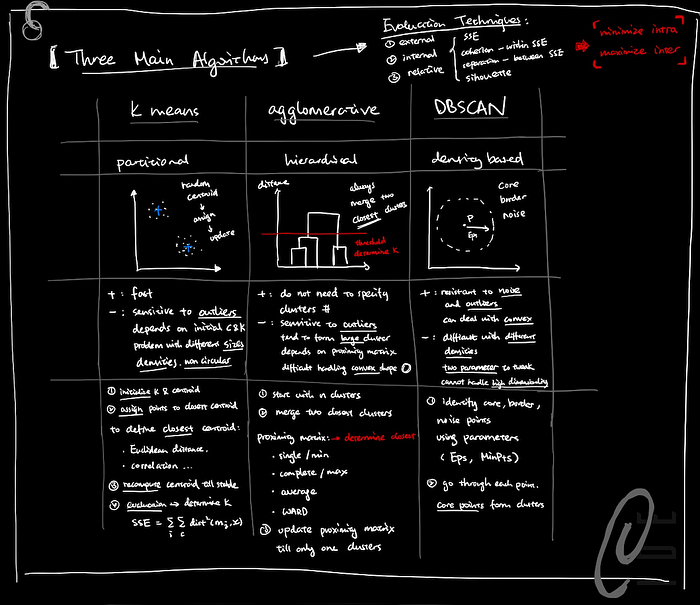
Support Vector Machine (SVM)
- classify the data based on the position in relation to a border between positive class and negative class
- create a hyperplane to maximize the margin
- introduce complexity parameter to minimize the classification error
Extensions of SVM
- using Kernel Tricks when instances are not linearly separable (including polynomial kernel and RBF kernel)
- SVM Regression: transform classification problem into regression
- Multi-Class SVM: deal with non-binary classification
4. Bayesian Learning
Bayesian Theorem:
Bayes’ Theorem provides a direct method of calculating the probability of such a hypothesis based on its prior probability, the probabilities of observing various data given the hypothesis, and the observed data itself

Bayesian Classifiers:
 Bayes Optimal Classifier
Bayes Optimal Classifier
- explicitly search through hypothesis space
- weighing the hypothesis prediction with the posterior probability of the hypothesis
A Gentle Introduction to the Bayes Optimal Classifier - AI Development Hub
The Bayes Optimum Classifier is a probabilistic mannequin that makes probably the most possible prediction for a brand…
aidevelopmenthub.com
Naive Bayes Classifier
- assume that attributes are independent of each other
- describe instances by a conjunction of attribute values
Naive Bayes Classifiers - GeeksforGeeks
Bayes' Theorem finds the probability of an event occurring given the probability of another event that has already…
www.geeksforgeeks.org
Bayesian Network
- taken into consideration of conditional dependencies among attributes
- use a simple, graphical notation for conditional independence assertions and hence for a compact specification of full joint distributions
- use conditional probability table to represent the conditional dependency
A Gentle Introduction to Bayesian Belief Networks - Machine Learning Mastery
Probabilistic models can define relationships between variables and be used to calculate probabilities. For example…
5. Reinforcement Learning
Problems involving an agent interacting with an environment which provides reward; the goal is to learn how to take actions in order to maximize reward
Markov Decision Process (MDP)

- a mathematical formulation of the reinforcement problem
- to find an optimal policy that maps the state to action, aiming for maximizing value function
Reinforcement Learning Demystified: Markov Decision Processes (Part 1)
Episode 2, demystifying Markov Processes, Markov Reward Processes, Bellman Equation, and Markov Decision Processes.
Q Learning

- An agent learns an evaluation function over states and actions iteratively often when MDP with unknown reward and transition functions.
- for each state and each action of that state: Q(s,a) is updated based on immediate reward of current r(s, a), and the discounted reward for the successor state
- value iteration works even if randomly traverse the environment, but we must visit each state infinitely often on an infinite run in order to converge to the optimal policy
A Beginners Guide to Q-Learning
Model-Free Reinforcement Learning
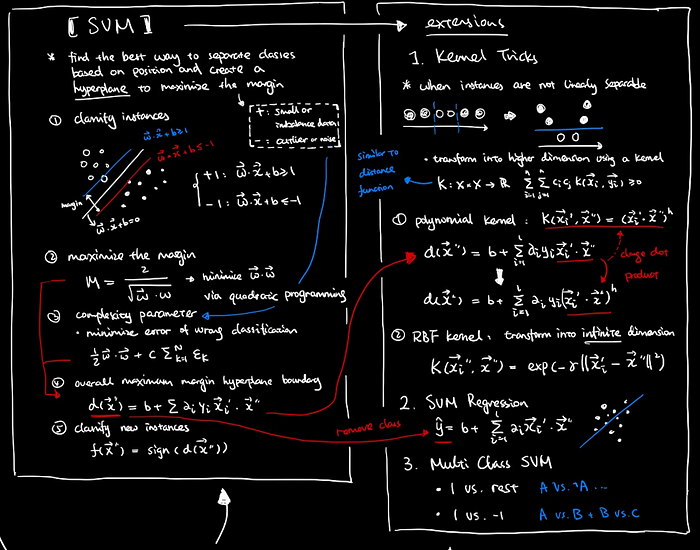
6. Data Preprocessing
Deal with Incomplete Data
- ignore the tuple
- fill in missing data manually
- fill in automatically: using global constant, attribute mean or most probable value
- matrix decomposition approaches
- multiple imputations
Deal with Noisy Data
- binning
- regression
- clustering
Deal with Redundant Data
- feature selection techniques such as correlation, heuristic search, relief or wrapper
- Principal Component Analysis (PCA)
Deal with Imbalance Data
- oversampling minority or undersampling majority
- clustering-based oversampling
- SMOTE
How to Deal with Imbalanced Data using SMOTE
With a Case Study in Python
7. Anamoly Detection
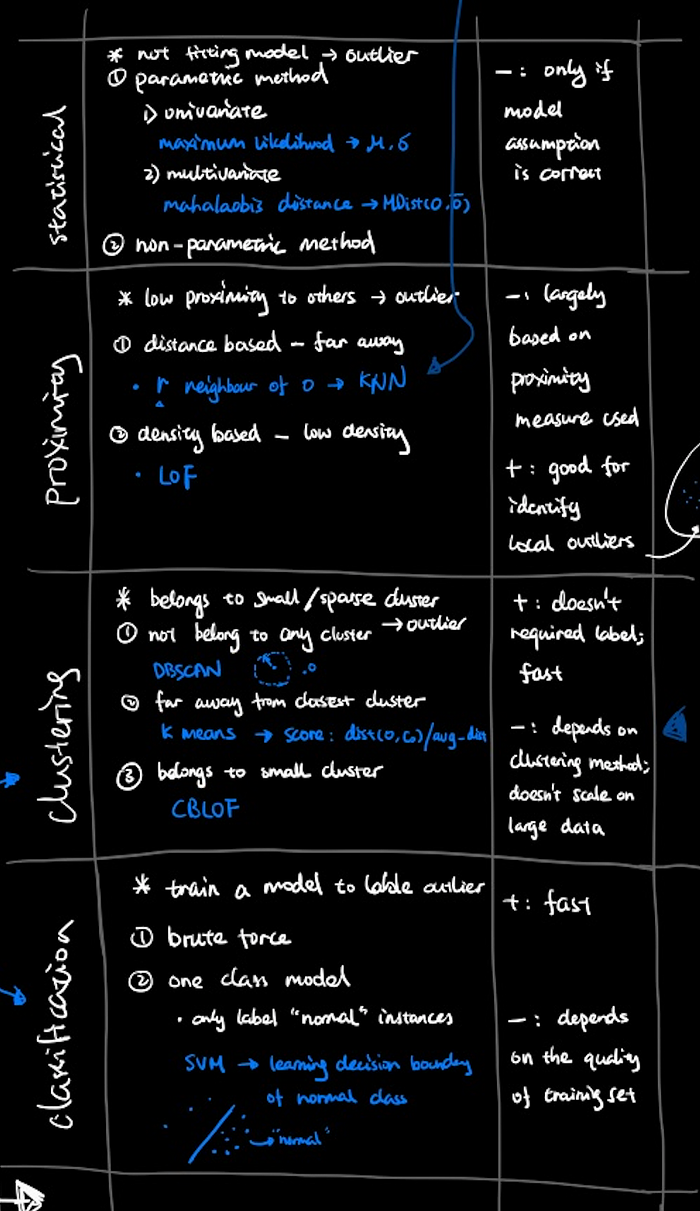
Statistical-Based Methods
- assume that normal data follows some statistical model
- two types of statistical model:
- univariate model
- multivariate model
Proximity-Based Methods
- r neighbour of o: distance-based proximity measure
- local outlier factor (LOF): density-based proximity measure
Local Outlier Factor for Anomaly Detection
Short summary about the Local Outlier Factor (LOF)
Clustering-Based Methods
- DBSCAN: when outliers not belonging to any cluster
- k means: when outliers far away from closest cluster
- cluster-based local outlier factor (CBLOF): when outliers form small clusters
Classification-Based Methods
- Brute Force Algorithm
- SVM: learning the boundary between normal data and outliers
8. Data Stream Mining
The process of extracting knowledge structures from a real-time, continuous, ordered sequences of items.
Change Drift Detector:

- CUSUM (sequential analysis): detect change drift by comparing threshold and drift speed
- DDM (statistical process control): controlled by drift level and warning level
- ADWIN (adaptive sliding window): capture the changes in error rate using exponential histogram
Classifier:

- baseline classifiers: such as majority class classifier, lazy classifier. decision tree etc
- Hoeffding Tree: decide whether to grow the tree based on the upcoming instances
- Hoeffding Adaptive Tree: combine Hoeffding Tree with ADWIN, therefore able to make adaptive change according to concept drift
- other extensions of Hoeffding Tree: VDFT, CVFDT …
- Ensemble Classifiers: OzaBag, Adaptive Random Forest
Machine Learning for Data Streams
A central feature of the data stream model is that streams evolve over time, and algorithms must react to the change…
Take-Home Message
 This is an overview of some essential topics in Machine Learning, including instance-based learning, clustering, association rule mining, Bayesian learning, reinforcement learning, data preprocessing, anomaly detection and data stream mining. Additionally, algorithms and core concepts under each topic were briefly introduced. The article mainly serves the purpose of categorizing and comparing concepts at an abstract level. Detailed explanations of each topic will be coming along with future articles …
This is an overview of some essential topics in Machine Learning, including instance-based learning, clustering, association rule mining, Bayesian learning, reinforcement learning, data preprocessing, anomaly detection and data stream mining. Additionally, algorithms and core concepts under each topic were briefly introduced. The article mainly serves the purpose of categorizing and comparing concepts at an abstract level. Detailed explanations of each topic will be coming along with future articles …

























