Artificial Neural Networks Simplified!

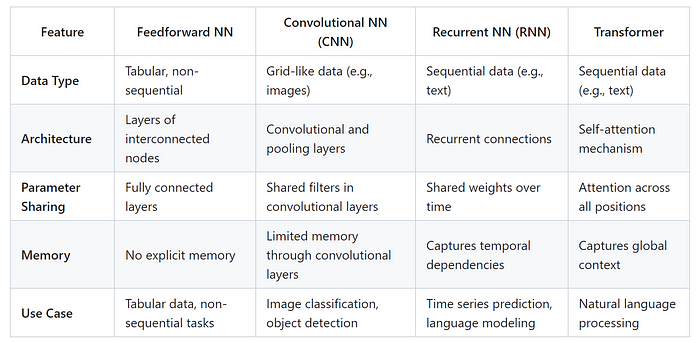
In the world of artificial intelligence, neural networks are like superheroes with different powers. Let’s dive into the easy-to-understand features of feedforward networks, Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and the Transformer model, exploring how they work and what they’re good at.
Feedforward Neural Networks
Think of feedforward networks as decision-makers. They take information and make predictions or classifications. Imagine them like a flowchart — you put in data, it goes through different steps, and out comes an answer. These networks use a learning process to improve their decision-making over time. Feedforward networks can solve simple classification and regression problems.
Classification:
- Goal: In classification, the aim is to categorize input data into predefined classes or categories. The algorithm learns from labeled training data where each example is associated with a specific class label.
- Example: An email spam filter is a classic example of classification. The algorithm is trained on a dataset of emails labeled as either “spam” or “not spam.” Once trained, it can predict the class of new, unseen emails.
- Output: The output of a classification model is a discrete class label or category.
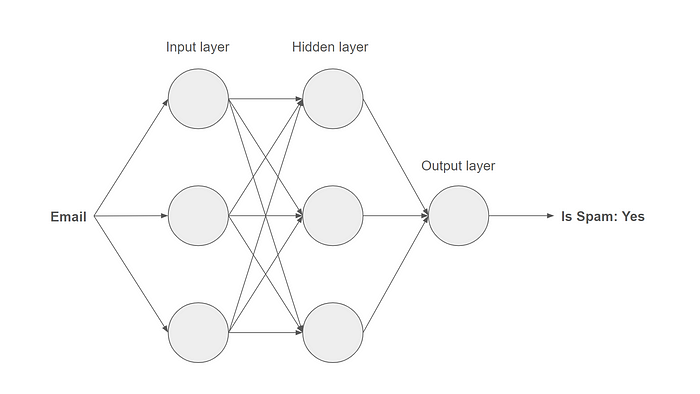 A Simplified neural network for spam detection
A Simplified neural network for spam detection
Regression:
- Goal: Regression, on the other hand, is concerned with predicting a continuous quantity or numeric value. The algorithm learns from labeled training data where each example is associated with a numerical target value.
- Example: Predicting house prices based on features like square footage, number of bedrooms, and location is a common regression task. The algorithm learns from a dataset where each house is associated with its actual sale price.
- Output: The output of a regression model is a numeric value that can be any real number within a specified range.
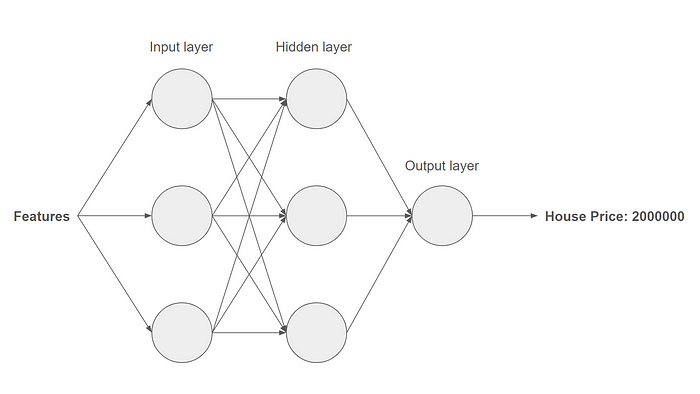 A Simplified neural network for house price prediction
A Simplified neural network for house price prediction
Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs) are a class of deep learning models designed to process and analyze visual data, making them particularly effective for tasks like image recognition, object detection, and image segmentation. The key features of CNNs that enable their success in computer vision tasks are convolutional layers, pooling layers, and fully connected layers.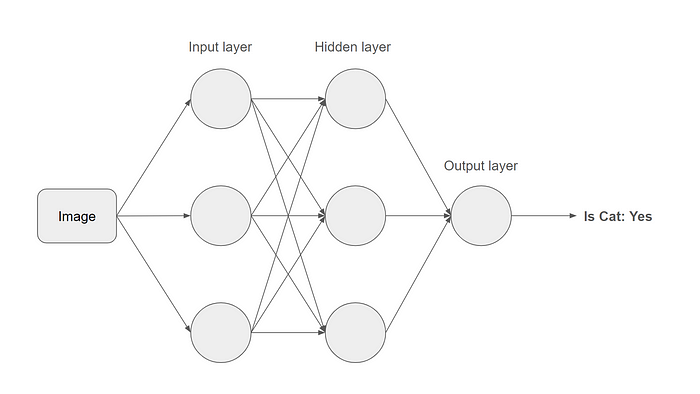 A Simplified neural network for image recognition
A Simplified neural network for image recognition
Here’s a simplified explanation of how CNNs work:
Convolutional Layers:
- CNNs use convolutional layers to scan the input image with small filters or kernels. These filters detect local patterns, such as edges, corners, and textures.
- The convolution operation involves sliding the filter over the input image, multiplying the filter values with the corresponding pixel values, and summing up the results. This process creates a feature map that highlights the presence of specific patterns.
Activation Function:
- After the convolution operation, an activation function (commonly ReLU — Rectified Linear Unit) is applied element-wise to introduce non-linearity. This helps the network learn complex patterns and relationships in the data.
Pooling Layers:
- Pooling layers are used to downsample (Reduce noise in the image) the spatial dimensions of the feature maps while retaining important information. Max pooling is a common technique where the maximum value in a small region of the feature map is selected, effectively reducing the size of the representation.
Flattening:
- After several convolutional and pooling layers, the feature maps are flattened into a one-dimensional vector. This step prepares the data for input into fully connected layers.
Fully Connected Layers:
- The flattened vector is passed through one or more fully connected layers, which are similar to the layers in traditional neural networks. These layers learn to combine high-level features from the convolutional layers to make predictions.
Output Layer:
- The final fully connected layer produces the network’s output. In classification tasks, it often uses a softmax activation function to generate probabilities for each class. The class with the highest probability is the predicted output.
Training:
- CNNs are trained using a labeled dataset. The model learns to adjust its internal parameters (weights and biases) during training by minimizing the difference between its predictions and the actual labels using a loss function. Backpropagation and optimization algorithms (e.g., gradient descent) are used to update the parameters.
In summary, CNNs automatically learn hierarchical features from input images through the use of convolutional filters, enabling them to recognize patterns and make accurate predictions in visual tasks. The convolutional and pooling layers help capture spatial hierarchies, while fully connected layers combine this information for the final output.
Recurrent Neural Networks (RNNs)
Recurrent Neural Networks (RNNs) are a class of artificial neural networks designed to handle sequential data(audio, video, language(grammar), etc.) by incorporating memory and capturing dependencies over time. Unlike traditional neural networks, RNNs have connections that create loops, allowing information to persist.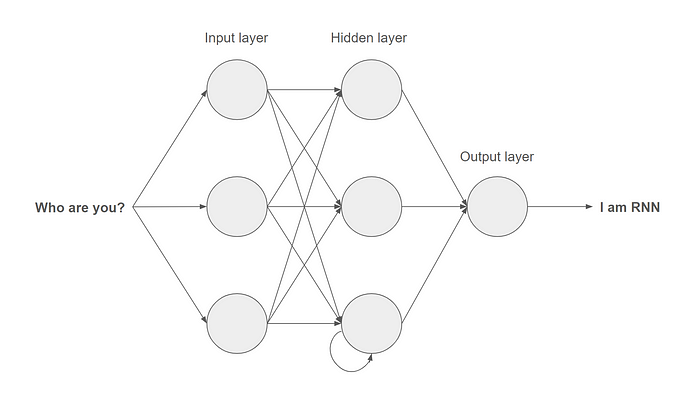 A Simplified neural network for Natural Language Processing(NLP)
A Simplified neural network for Natural Language Processing(NLP)
Here’s a simplified explanation of how RNNs work:
Sequential Data Handling:
- RNNs are well-suited for sequential data, such as time series, natural language, and speech. The network processes input sequences one element at a time, maintaining a hidden state that acts as memory.
Recurrent Connections:
- The defining feature of RNNs is their recurrent connections. At each time step, the network takes the input and combines it with the hidden state from the previous time step. This process allows RNNs to maintain information about past inputs and learn patterns over sequences.
Hidden State and Memory:
- The hidden state of the RNN acts as a form of memory that retains information about previous inputs. As the network processes each element in the sequence, it updates its hidden state, effectively capturing the context and dependencies within the data.
Training and Backpropagation Through Time (BPTT):
- RNNs are trained using a process called Backpropagation Through Time (BPTT). Similar to traditional neural networks, RNNs learn from labeled data by adjusting their internal parameters (weights and biases) to minimize the difference between predicted and actual outcomes.
- BPTT involves unfolding the recurrent connections over multiple time steps and applying the backpropagation algorithm. This allows the network to learn how to update its hidden state and make predictions based on sequential dependencies.
Long Short-Term Memory (LSTM):
- Traditional RNNs struggle with capturing long-range dependencies due to the vanishing gradient problem. To address this issue, more advanced RNN architectures, such as Long Short-Term Memory (LSTM), were introduced. LSTMs include specialized memory cells and gating mechanisms that enable them to selectively store and retrieve information over longer sequences.
Gated Recurrent Unit (GRU):
- Another variation of RNNs is the Gated Recurrent Unit (GRU), which simplifies the architecture compared to LSTM but still addresses the vanishing gradient problem. GRUs use gating mechanisms to control the flow of information through the network, allowing them to capture dependencies effectively.
In summary, RNNs are designed to handle sequential data by maintaining a hidden state that captures information about previous inputs. The recurrent connections and training mechanisms of RNNs enable them to learn patterns and dependencies in sequential data, making them suitable for a wide range of applications, including natural language processing, time series analysis, and speech recognition. Advanced versions like LSTM and GRU enhance their ability to capture long-range dependencies and mitigate common challenges.
Transformer Model
Transformers represent a significant departure from traditional Recurrent Neural Networks (RNNs) and have become a dominant architecture(Large Language Models(LLMs) like GPT use a transformer model for training) in natural language processing and other sequential data tasks. It uses a mechanism called Self-Attention. We will further explore transformers in upcoming articles. Let’s explore transformers advantages over RNNs, along with some limitations of RNNs that transformers address:
Long-Term Dependencies:
- RNN Limitation: Traditional RNNs struggle to capture long-term dependencies due to the vanishing gradient problem. They have difficulty retaining information over many time steps.
- Transformer Solution: Self-attention mechanisms in transformers enable them to capture long-range dependencies effectively, as each position in the sequence can attend to any other position.
Parallelization:
- RNN Limitation: RNNs process sequences sequentially, limiting parallelization and making them computationally inefficient.
- Transformer Solution: Transformers process all positions simultaneously, allowing for parallelization across the sequence, resulting in faster training and inference.
Ease of Training:
- RNN Limitation: Training RNNs can be challenging due to the sequential nature of the computations and the difficulty of capturing long-term dependencies.
- Transformer Solution: Transformers are more amenable to parallel processing, making them easier to train efficiently, especially on modern hardware like GPUs and TPUs.
Scalability:
- RNN Limitation: As the length of sequences increases, the ability of RNNs to capture dependencies diminishes.
- Transformer Solution: Transformers maintain consistent performance regardless of sequence length, making them more scalable to handle longer inputs.
While transformers have shown great success, it’s important to note that they might not always be the best choice for every task. They may require a large amount of data for training and can be computationally intensive. Additionally, transformers might not perform optimally on tasks where sequential processing is crucial, and the order of elements matters significantly(Parallelization of transformer model limits performance in serial data like real-time audio). In such cases, variations of RNNs like LSTMs or GRUs may still be relevant. The choice between RNNs and transformers often depends on the specific characteristics of the data and the nature of the task at hand.
Summary